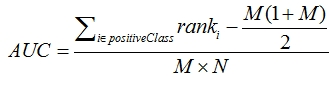AUC(Area under the Curve of ROC)是衡量机器学习模型效果的非常重要的一个指标,也是模型上线后算法同学较为关心的一个指标,它能评判模型预测的准确度。为了提升模型效果,结合DNN模型可以进行增量训练的特点,我们提高了模型的迭代更新频率,有些模型甚至可以做到一天一更新。原来一天计算一次AUC的方案已经难以满足现在的需求,算法同学希望能看到模型的实时AUC,及时评估线上模型的效果,于是我们开始探索如何实时计算线上模型的AUC。
AUC有一个性质是,它与Mann–Whitney U test是等价,该测试就是任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score,而这个概率值就是AUC。统计学中,我们可以通过统计频率来估计概率。取所有的正负样本对,计算正样本score大于负样本score的数量(正负样本score相等时取0.5),然后除以样本对数,便可得到AUC。 这种方法经过推导可以得到如下公式, 其中M是正样本的数目,N为负样本的数目
createtable dx.tmp_check_auc_data as select modelVersion, sessionId, hotelId, cvr, ctr, booking_bool, click_bool from logtable join impressiontable on logtable.sessionId=impressiontable.sessionId and logtable.hotelId=impressiontable.hotelId leftjoin ordertable on impressiontable.sessionId=ordertable.sessionId leftjoin clicktable on impressiontable.sessionId=clicktable.sessionId
select modelVersion, (ry -0.5*n1*(n1+1))/n0/n1 as auc from ( select modelVersion ,sum(if(booking_bool=0, 1, 0)) as n0 ,sum(if(booking_bool=1, 1, 0)) as n1 ,sum(if(booking_bool=1, cvr_rank, 0)) as ry from ( select modelVersion, booking_bool, cvr , row_number() over(partitionby modelVersion orderby cvr asc) as cvr_rank from dx.tmp_check_auc_data where modelVersion isnotnull ) groupby modelVersion )
select t, modelVersion, arrayAUC(cvr_arr, order_arr) as auc from ( select modelVersion, t, groupArray(cvr) as cvr_arr, groupArray(book_bool) as order_arr from (SELECT a.hotelId, cvr, modelVersion, a.sessionId as sessionId, toUInt32(toStartOfFifteenMinutes(impressTime)) *1000as t, casewhen e.sessionId !=''then1else0endas book_bool FROM ( SELECT hotelId, cvr, modelVersion, sessionId, impressTime FROM auc.hotel_impress_all WHERE and impressTime >= $from AND impressTime < $to ) a GLOBAL leftOUTERjoin ( SELECT sessionId, hotelId FROM auc.hotel_click_all WHERE eventTime >=$from AND eventTime < $to ) d on a.sessionId = d.sessionId and a.hotelId = d.hotelId GLOBAL leftOUTERjoin ( SELECT sessionId, hotelId FROM auc.hotel_order_all WHERE eventTime >= $from AND eventTime < $to ) e on a.sessionId = e.sessionId and a.hotelId = e.hotelId) groupby t, modelVersion ) orderby t
select t, modelVersion, (ry -0.5* n1 * (n1 +1)) / n0 / n1 from (select modelVersion, toUInt32(toStartOfFifteenMinutes(eventTime)) *1000as t, sum(if(book_bool =0, 1, 0)) as n0, sum(if(book_bool =1, 1, 0)) as n1, sum(if(book_bool =1, cvr_rank, 0)) as ry FROM (SELECT modelVersion, cvr_rank, eventTime, book_bool from (SELECT modelVersion, groupArray(book_bool) as arr_book_bool, groupArray(sessionId) as arr_sessionid, groupArray(hotelId) as arr_htlId, groupArray(cvr) as arr_cvr, groupArray(eventTime) as arr_eventTime, arrayEnumerate(arr_cvr) AS cvr_rank FROM (SELECT hotelId, cvr, modelVersion, a.sessionId as sessionId, impressTime as eventTime, casewhen e.sessionId !=''then1else0endas book_bool FROM ( SELECT hotelId, cvr, modelVersion, sessionId, impressTime FROM auc.hotel_impress_all WHERE impressTime >= $from AND impressTime < $to ) a GLOBAL leftOUTERjoin ( SELECT sessionId, hotelId FROM auc.hotel_order_all WHERE eventTime >= $from AND eventTime < $to ) e on a.sessionId = e.sessionId and a.hotelId = e.hotelId
ORDERBY cvr ) GROUPBY modelVersion, toUInt32(toStartOfFifteenMinutes(eventTime)) *1000as t) ARRAYJOIN arr_book_bool as book_bool, arr_sessionid as sessionId, arr_htlId as htlId, arr_cvr as cvr, arr_eventTime as eventTime, cvr_rank) groupby modelVersion, toUInt32(toStartOfFifteenMinutes(eventTime)) *1000as t)
@Override public void processElement(Object value, Context ctx, Collector<Object>out) throws Exception { //所有消息延迟10分钟 long timer = ctx.timerService().currentWatermark() +600; ctx.timerService().registerEventTimeTimer(timer); state.update(value); } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<Object>out) throws Exception { if (state.value() ==null) { return; } out.collect(state.value()); state.clear(); }
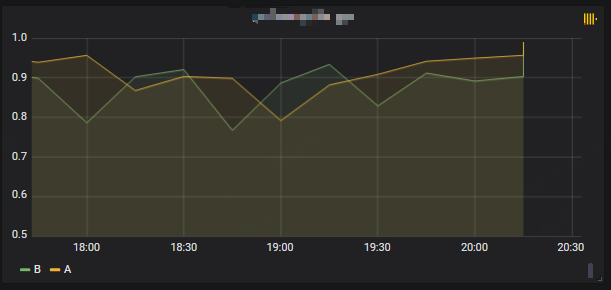
查询方法(一段时间内不同实验版本的AUC对比):
1 2 3 4 5 6 7 8
select modelVersion,arrayAUC(cvr_arr,order_arr) as auc from ( select modelVersion,groupArray(cvr) as cvr_arr,groupArray(book_bool) as order_arr from( select cvr, book_bool, modelVersion from auc_mv.impress_click_order_join_mv_all WHERE queryTime >= $from AND queryTime < $to) groupby modelVersion)
AS SELECT impress.hotelId AS hotelId, cvr, modelversion, impress.sessionId AS sessionId, impress. eventTime as eventTime, orderId, a.sessionId as if_order, a.eventTime as orderTime FROM ( SELECTdistinct sessionId, hotelId, orderId, eventTime FROM auc.hotel_order ) a GLOBAL rightjoin ( SELECT hotelId, cvr, modelversion, sessionId, eventTime FROM auc.hotel_impress_all where eventTime >= toDateTime(now() -1800) ) as impress on impress.hotelId = a.hotelId and impress.sessionId = a.sessionId;
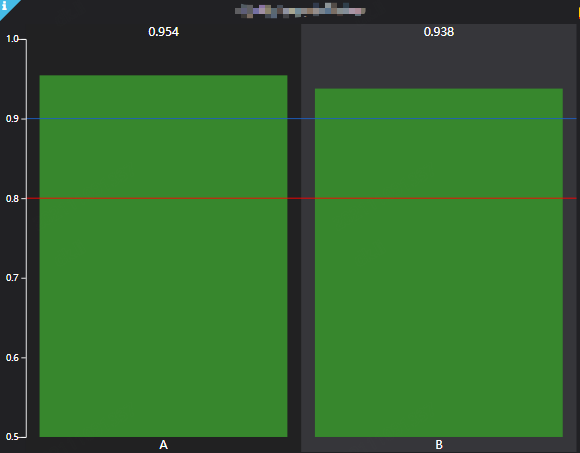
查询方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
select modelversion, arrayAUC(cvr_arr, order_arr) as auc from ( select modelversion, groupArray(cvr) as cvr_arr, groupArray(order_bool) as order_arr from ( select modelversion, cvr, casewhen if_order !=''then1else0endas order_bool from ( selectdistinct cvr, modelversion, eventTime, if_order from auc.impress_order_join WHERE eventTime >= $from AND eventTime < $to ) ) groupby modelversion )